Maple
Powerful math software that is easy to use
• Maple for Academics • Maple for Students • Maple Learn • Maple Calculator App • Maple for Industry and Government • Maple for Individuals
Maple Add-Ons
• E-Books & Study Guides for Students • Maple Toolboxes • MapleNet • Free Maple Player
Math Success Platform
Math success in the age of AI
Maple Flow
Engineering calculations & documentation
• Maple Flow • Maple Flow Migration Assistant





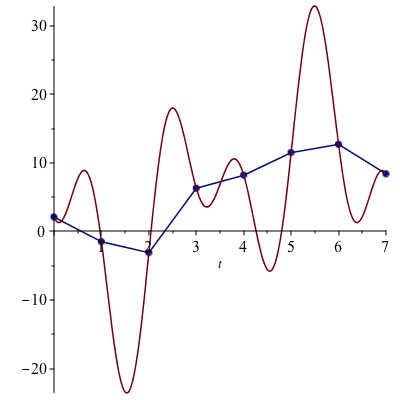
![Points := rtable(1 .. 8, 1 .. 2, [[0., 2.1], [1., -1.5], [2., -3.1], [3., 6.3], [4., 8.2], [5., 11.5], [6., 12.7], [7., 8.4]], subtype = Matrix); -1](Connectivity/Connectivity_61.gif)






![DataFrame(_rtable[18446744074844130830], rows = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, ...](Connectivity/Connectivity_105.gif)